
Text representation in NLP
Introduction
To effectively process textual data, it is crucial to convert it into a numeric representation compatible with the chosen algorithm. After completing all the preprocessing steps outlined in the previous blog, what remains is a variable-length sequence of symbols. Most machine learning algorithms are designed to work with fixed-length numeric vectors. As a result, after completing the necessary preprocessing steps on text data, the next crucial step is to convert the preprocessed text into vectors.

For NLP tasks, features could be word count, document age, encodings, vectorized texts or some other metadata. These features are utilized to construct a feature vector, which essentially are grouped together to form a matrix representation, as depicted below.
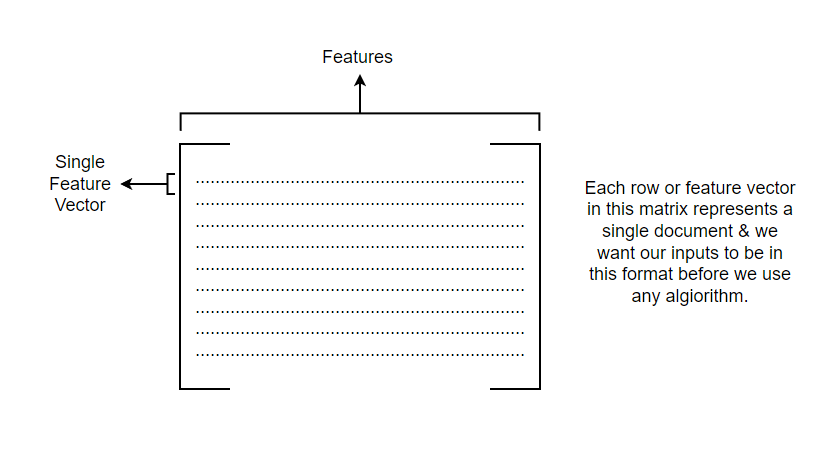
In our pursuit of feature vectors that effectively encode the semantics and meaning of a document while capturing its linguistic properties, we encounter a diverse array of methods. This blog will delve into a selection of these techniques, providing valuable insights into how they achieve their objectives.
Bag of Words
One of such approaches is bag-of-words or BOW, which is a general technique to describe documents by word presence. The primary idea is that the meaning and similarity are encoded in vocabulary. i.e. similar documents share similar vocabulary. Let’s look at it using example:
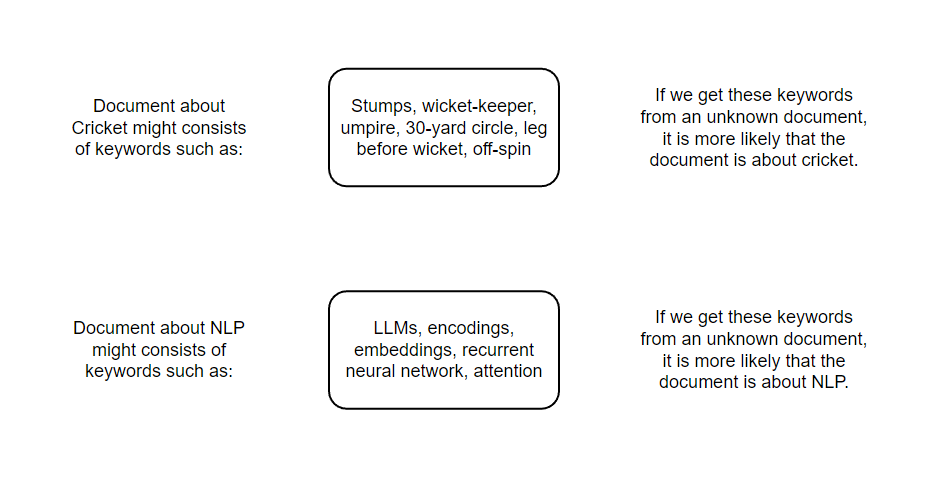
But if we compare keywords from cricket documents and NLP documents, none of the keywords match. So, we can infer that these documents are not similar at all & they are not similar in reality as well.
The fundamental concept behind similarity lies in the existence of overlapping vocabulary. In other words, documents that share common words are more likely to belong to the same category. The “Bag” representation in the Bag-of-Words (BOW) model does not take into account the word order and only considers whether a word occurred or not, and possibly its frequency of occurrence.
In the Bag-of-Words (BOW) approach, we begin with a vocabulary comprising various unique words and each word is assigned a unique position. When processing a document, each word present in the document is assigned a value of 1, while all other words are assigned a value of zero. This process generates a feature vector that represents the document based on its word occurrences.

The matrix generated through this approach arranges documents in rows, with each column corresponding to a single term or token. However, the example mentioned above employs a binary Bag of Words (BOW) representation, which lacks the ability to capture word frequencies. To account for word frequency, we can switch to a frequency-based BOW representation.
Upon encoding, documents can be perceived as points in space, transcending mere words and symbols. This approach of representing sentences using the Bag of Words (BOW) technique in space is commonly referred to as the Vector Space Model (VSM). And the similar documents will be closer in space while dissimilar will be far away. That particular distance in space can be calculated using the distance formula or we can even use metrics such as cosine similarity. This can be really helpful in categorizing documents, checking plagiarism etc.
However, this approach has several limitations. Firstly, it fails to recognize the similarity between synonyms and words with closely related meanings, disregarding essential nuances in language. Secondly, it completely ignores word order, which can be crucial in capturing context and meaning. Additionally, the method lacks a mechanism to handle out-of-vocabulary words, which represents a significant drawback and it also results in excessively sparse matrices, leading to unnecessary computational overheads.

The second problem mentioned in the example above can be mitigated using an approach called n-grams.
N-grams
N-grams is a powerful technique that leverages continuous sequences of tokens. Up until now, we have focused on individual tokens, known as unigrams. However, N-grams go beyond this by considering combinations of N tokens in a sequence. For instance, we have bi-grams (2-grams) and tri-grams (3-grams), which explore pairs and triplets of tokens, respectively, offering more context and information in natural language processing tasks. For Example:
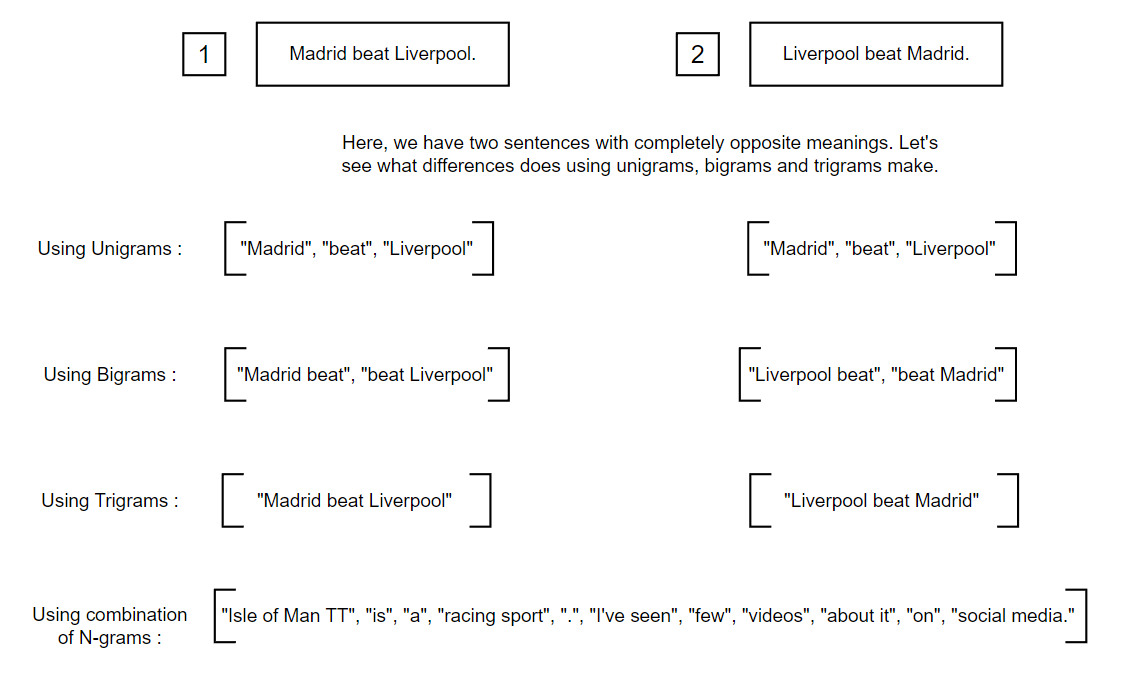
From the example above, It is evident that when employing unigrams, both sentences have identical token representations, but the distinction arises when we utilize bigrams and trigrams, enabling a more comprehensive context capture. Moreover, there is no compulsion to restrict ourselves to using unigrams, bigrams, or trigrams consistently across the entire corpus. Instead, a more effective approach involves combining different N-grams to achieve enhanced context and comprehension just like the last example above.
In our quest for improved text representation, we sought to address the limitations of binary Bag-of-Words (BOW) techniques, which treated all elements equally. To achieve this, we explored the usage of frequency-based BOW and N-grams. While these approaches offered some advantages, they exhibited certain drawbacks, such as skewness, inefficacy with out-of-vocabulary words, inability to handle synonyms, and undesirable high dimensionality.
TF-IDF
For some problems discussed in paragraph above, we can take corpus and take into account the relative frequency of words i.e. how often a token appears in one document vs how often it occurs in another document. For instance, if we have a collection of 10 documents and find that the word “x” appears significantly in only two of them, it signifies that “x” holds particular significance in those specific documents. On the other hand, if another word “p” repeats consistently across all the documents, it likely serves as a common stop word and lacks significant importance in the context of the analysis. One of the techniques for encoding this relative information is TF-IDF or Term Frequency - Inverse Document Frequency. There have been many variations of TF-IDF but here, we are going to learn the original one.
Calculating TF-IDF can be done in following manner :

The mere abundance of the term “lemon” in the second document, as compared to the first document, does not necessarily imply its greater significance in the second document. Various factors such as length of the document can influence word frequency. To address this issue, a suitable approach involves considering the logarithmic frequency.

Now, let’s calculate IDF.

The intuition behind IDF is that the fewer documents the term “t” appears in, higher will be the IDF value and more weight will be distributed to the word and vice versa.

Let’s understand it using an example:

n conclusion, Bag-of-Words (BoW) provides a simple and direct method for text representation, while TF-IDF offers a more refined and informative approach by considering the importance of words within the entire corpus. The selection between these techniques relies on the specific NLP task and the desired level of text representation complexity. Researchers and practitioners often explore both approaches to identify the most suitable one for their particular use case.
Furthermore, the field of NLP has seen the emergence of advanced techniques, such as word embeddings (e.g., Word2Vec, GloVe), which offer even more sophisticated ways to represent text data and capture semantic relationships. We’ll discuss more about NLP techniques in next blog.
References for this blog (Click on references for more info):
1. NLP Demystified (Full Course).
2. Word Representations in Natural Language Processing.
3. Understanding TF-ID: A Simple Introduction.
4. A Gentle Introduction to the Bag-of-Words Model.